



Context
Engineering
for AI Agents
Prompt Engineering told the model what to do. Context Engineering teaches it how to think — by precisely controlling everything that fills its context window: memories, tools, instructions, history, and live data. It is the craft behind every capable AI agent in 2025.
The Three Pillars of Context
Pillar One
What Goes In
Everything placed into the context window before the model reasons. This is your engineering surface.
- System prompt & persona
- Retrieved memories
- Tool schemas & outputs
- Conversation history
- User input + files
- Background knowledge
Pillar Two
How It’s Structured
The arrangement, format, and priority of context elements. Order and structure dramatically affect model behavior.
- XML / Markdown delimiters
- Priority ordering (top = high weight)
- Compression & summarization
- Chunking strategies
- Token budget management
- Few-shot example placement
Pillar Three
How It Evolves
Context is dynamic. Good context engineering manages its lifecycle across turns, tasks, and time.
- Memory write / read loops
- Context window pruning
- Re-injection strategies
- State serialization
- Long-horizon planning context
- Forgetting & summarizing
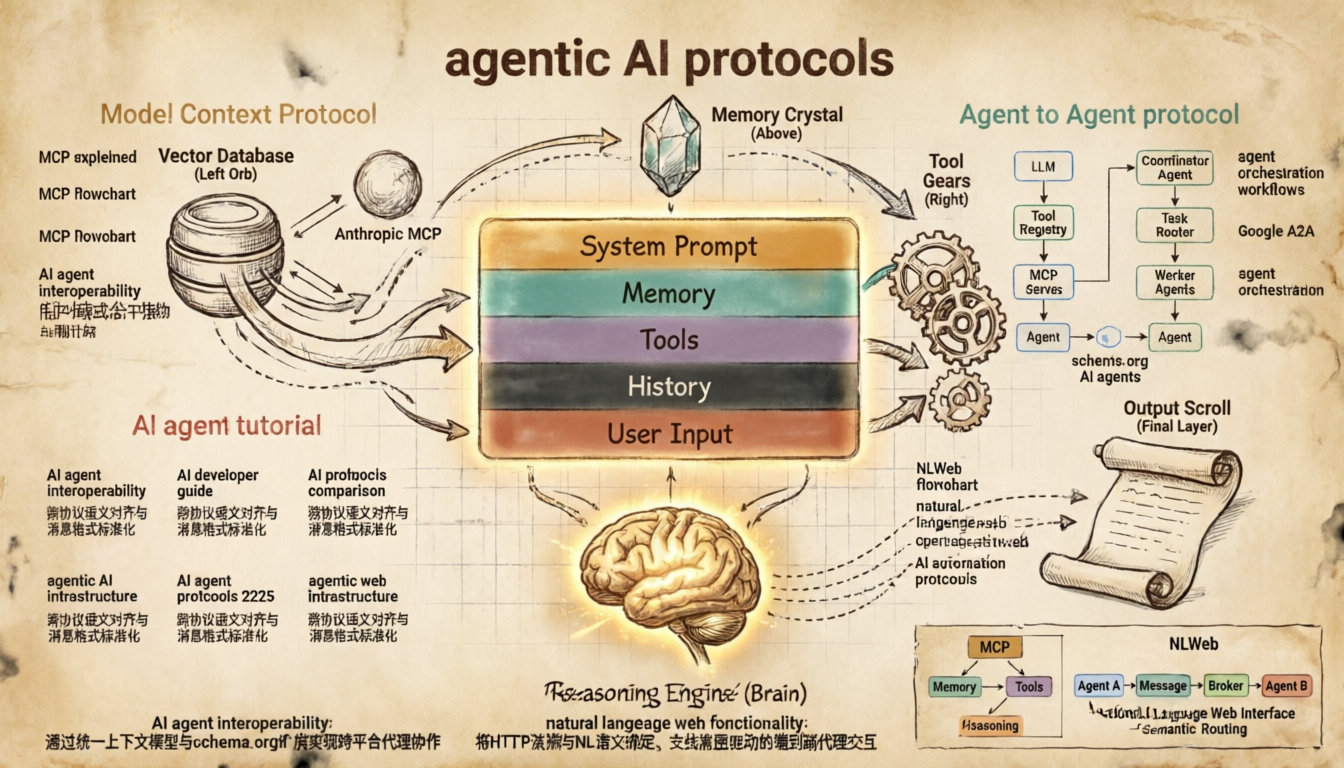
Anatomy of an Agent’s Context Window
Typical context window composition — a 200k token agent context
Context Engineering Lifecycle
The Full Context Engineering Loop — From User Input to Agent Response
Memory Architecture — Four Types of Agent Memory
Context Pruning Strategy — Managing the Token Budget
“The bottleneck in agent performance is rarely the model. It is almost always the quality of information you put in front of it.”
— Core principle of Context EngineeringContext Engineering in Practice
Customer Support Agent
Task: “I want to return the shoes I bought last week. They don’t fit.”
Engineered Context Window
[MEMORY] User: Sarah Chen. Tier: Premium. Past issues: 2 resolved. Preferred size: US9.
[TOOLS] lookup_order(id), initiate_return(order_id, reason), check_inventory(sku)
[INPUT] “I want to return the shoes I bought last week…”
- 1System prompt sets persona + policy constraints
- 2Memory injects customer profile (no need to ask who they are)
- 3Agent calls
lookup_order→ injects result into context - 4Calls
initiate_returnwith correct order ID - 5Response + interaction saved back to memory store
Autonomous Coding Agent
Task: “Add unit tests for the payment module and fix any bugs you find.”
Engineered Context Window
[MEMORY] Project: FastAPI app. DB: PostgreSQL. Pattern: Repository. Prior sessions: 3 bug fixes.
[FILES] payment.py (840 tokens), models.py (420 tokens) — retrieved via RAG
[TOOLS] read_file, write_file, run_tests, search_codebase
- 1RAG retrieves only relevant files (not entire codebase)
- 2Memory provides project conventions — no re-explaining needed
- 3Agent reads, writes tests, calls
run_tests - 4Test result injected back — agent iterates on failures
- 5Session summary written to long-term memory
Deep Research Agent
Task: “Write a competitive analysis of EV battery manufacturers.”
Engineered Context Window
[PLAN] Step 1: identify players. Step 2: gather data. Step 3: synthesize.
[SCRATCHPAD] [running notes & intermediate findings kept here, pruned as context fills]
[SOURCES] Retrieved articles injected progressively via RAG
- 1Plan injected upfront — agent follows structured reasoning
- 2Scratchpad in context stores intermediate work
- 3Sources retrieved progressively — old ones summarized & pruned
- 4Context budget managed: 60% sources, 30% reasoning, 10% output
- 5Final report written with full traceable citations
Long-Horizon Personal Assistant
Task: “Help me prep for my meeting with the investor tomorrow.”
Engineered Context Window
[MEMORY] Investor: James Wong, Sequoia. Past meeting notes. Alex’s pitch deck v3. Alex’s goals: $2M seed.
[CALENDAR] Meeting: 10am, 45 mins. Location: Zoom. Retrieved from calendar tool.
[INPUT] “Help me prep for my meeting…”
- 1Rich memory profile means zero context re-establishment
- 2Calendar tool call injects live meeting details
- 3Past notes retrieved — agent knows investor preferences
- 4Agent produces tailored prep briefing in seconds
- 5Post-meeting: outcome saved to long-term memory
Key Techniques Reference
| Technique | Category | What It Does | When To Use |
|---|---|---|---|
| RAG (Retrieval-Augmented Generation) | Context Filling | Fetches relevant documents from a vector DB and injects them into context at query time. Grounds the model in real, up-to-date knowledge. | Large knowledge bases, dynamic data, reducing hallucinations |
| Sliding Window | History Management | Keeps only the N most recent conversation turns in context. Older turns are dropped or summarized to make room for new input. | Long-running chatbots, multi-turn agents with token limits |
| Hierarchical Summarization | Compression | Progressively summarizes earlier parts of a conversation into increasingly dense summaries, preserving meaning while reducing tokens. | Long research sessions, hours-long agent tasks |
| Scratchpad / Chain-of-Thought | Reasoning Aid | Dedicated section in context for intermediate reasoning steps. Lets the model “think out loud” before committing to a final answer. | Complex multi-step tasks, planning, debugging |
| Few-Shot Examples | Behavior Shaping | Inject 2–5 high-quality input/output pairs into context to demonstrate desired format, tone, and reasoning style. | Structured outputs, specialized formats, consistent tone |
| Prompt Caching | Efficiency | Prefix parts of the context (e.g. system prompt + tools) for reuse across many calls. Dramatically reduces latency and cost. | High-volume applications, static system prompts |
| Tool Result Injection | Agentic Loop | After tool execution, the result is inserted back into context in a structured format so the model can reason about it in the next step. | All agentic tool-use scenarios |
| Semantic Memory Retrieval | Long-Term Memory | Stores past interactions as vector embeddings. At runtime, retrieves the most semantically similar past facts and injects them into context. | Personalized assistants, cross-session continuity |
| Priority-Based Ordering | Structure | Places the most critical instructions at the top of context (highest attention weight). Less important content goes later or is summarized. | All agent systems — always apply this principle |
| XML / Markdown Delimiters | Structure | Uses explicit tags like <system>, <memory>, <tools> to help the model distinguish between different types of context content. | Complex contexts with multiple distinct sections |