Step 1: Problem Definition
THE FOUNDATION OF EVERY SUCCESSFUL ML PROJECT
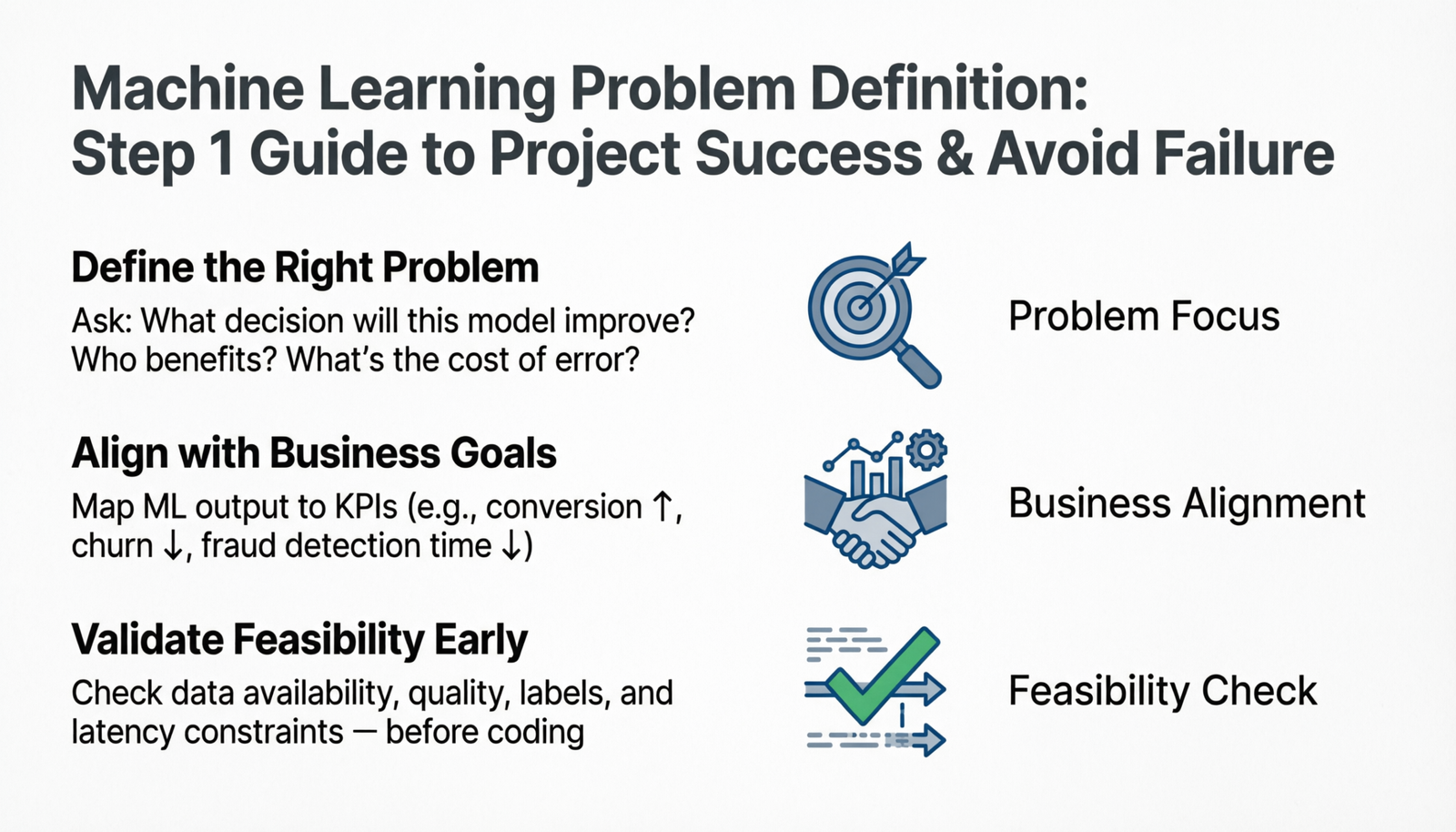
Why Problem Definition Matters
Problem definition is the crucial first step in any machine learning project. It’s where you clearly articulate what you’re trying to achieve, what you want to predict or classify, and how success will be measured. A well-defined problem is already halfway to being solved.
⚡ Critical Truth
According to industry research, 70% of ML projects fail not due to technical limitations, but because of poorly defined problems. Clear problem definition reduces development time by up to 40% and significantly increases the likelihood of project success.
Before writing a single line of code or collecting any data, you must answer fundamental questions about your problem. This step determines everything that follows: your data requirements, model selection, evaluation metrics, and ultimately, the business value of your solution.
Define the Core Objective
Clearly state what you want to achieve in simple, specific terms. Avoid vague goals like “improve business” or “use AI.” Instead, focus on concrete, measurable outcomes.
Essential Questions to Answer:
Example: Good vs Poor Problem Definitions
Identify Problem Type
Categorize your problem into one of the standard ML problem types. This determines your model architecture, evaluation metrics, and solution approach.
Classification Problems
Regression Problems
Other Problem Types
Specify Success Metrics
Define how you’ll measure whether your model is successful. Choose metrics that align with business objectives and the problem type.
Metric Selection Guide:
Example: Metric Selection
Define Constraints & Requirements
Identify technical, business, and operational constraints that will impact your solution design.
Key Constraints to Consider:
Example: Constraint Definition
Identify Stakeholders & End Users
Understand who will use your model and how it fits into existing workflows. This influences design decisions and success metrics.
Stakeholder Analysis:
Patient Readmission Prediction
House Price Prediction
Credit Card Fraud Detection
Customer Churn Prediction
Product Recommendation
Content Moderation
Best Practices for Problem Definition
🎯 Be Specific
Avoid vague objectives. Instead of “improve sales,” specify “predict customer purchase probability within 7 days with 80% accuracy.”
📊 Start Simple
Begin with the simplest version of the problem. You can always add complexity later once the baseline works.
💬 Talk to Stakeholders
Interview domain experts, end users, and business stakeholders. Their insights reveal hidden requirements and constraints.
📈 Align with Business Goals
Connect your ML metrics to business KPIs. A 95% accuracy model that doesn’t drive revenue is worthless.
🔄 Iterate Early
Refine your problem definition as you learn more. It’s okay to pivot based on data exploration and early experiments.
📝 Document Everything
Create a problem statement document. Include objectives, metrics, constraints, and assumptions for future reference.