




Entity Extraction
& Knowledge Graph
Construction
How autonomous agents parse unstructured text, resolve entities, and weave them into a living graph of interconnected knowledge.
What is Entity Extraction?
Named Entity Recognition (NER)
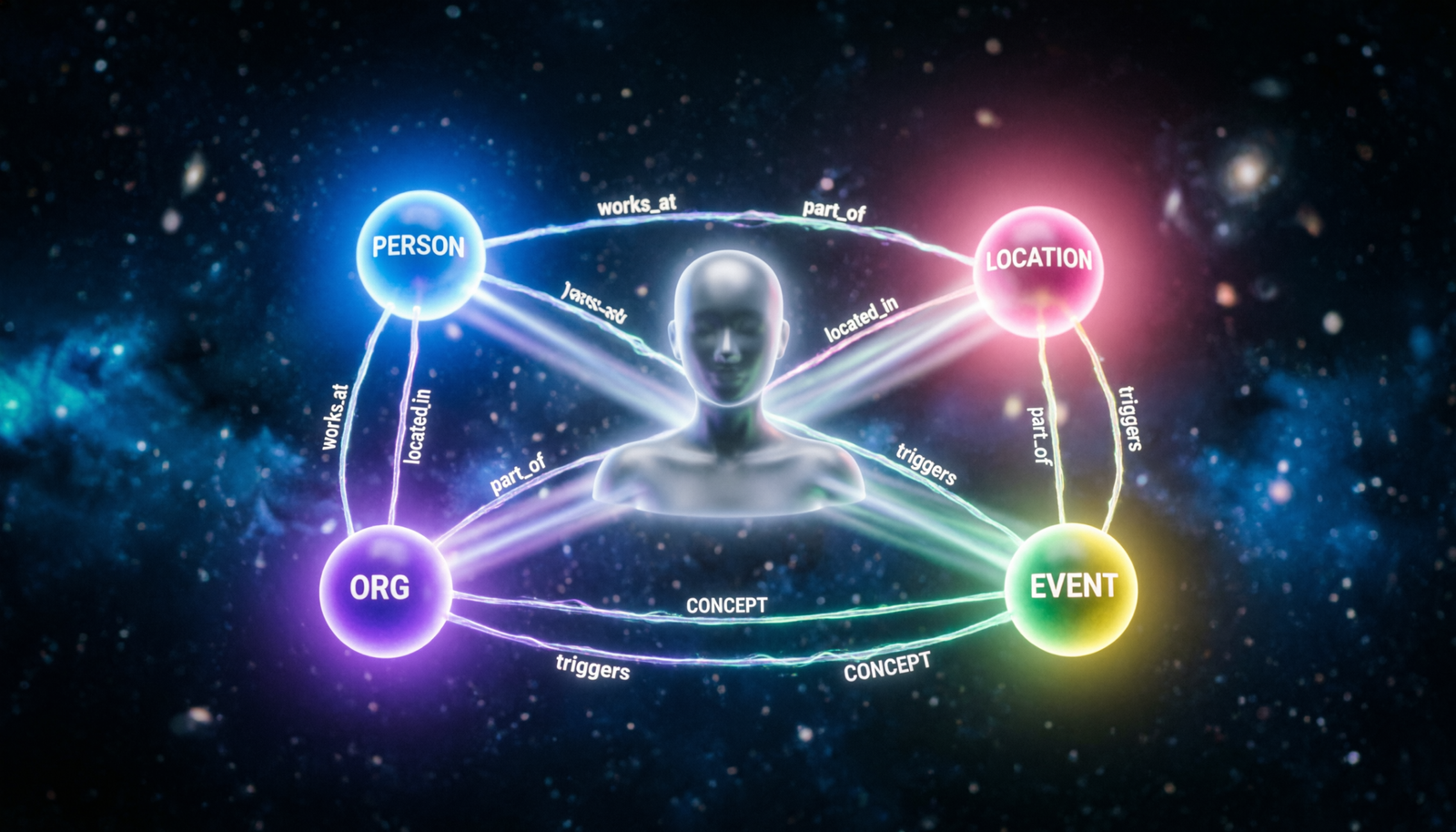
Identifies and classifies named mentions in raw text — people, places, organisations, dates, products — into pre-defined semantic categories.
Relation Extraction
Detects typed relationships between entity pairs: founded_by, located_in, acquired. Transforms flat text into structured semantic triples.
Coreference Resolution
Chains all mentions that refer to the same real-world entity (pronouns, aliases, acronyms) to produce a unified, deduplicated entity set.
Entity Linking
Maps extracted surface forms to canonical entries in a knowledge base (Wikidata, DBpedia) providing rich, standardised attributes for free.
Attribute Extraction
Pulls structured properties — dates, quantities, roles — directly from text and attaches them as typed attributes on graph nodes.
Event Extraction
Captures temporally-grounded events with participants, locations and timestamps, enabling reasoning over what happened, when, and to whom.
Common Entity Types
Extraction Pipeline for Agents
Document Ingestion & Chunking
Raw documents (PDFs, HTML, transcripts) are segmented into context-aware chunks preserving sentence boundaries. Metadata (source, timestamp, author) is attached at this stage.
LLM-Powered NER & Relation Extraction
Each chunk is passed to a fine-tuned LLM with a structured JSON output schema. The model simultaneously identifies entities and their typed relationships in a single forward pass.
Coreference & Deduplication
A resolution step clusters surface-form variants of the same entity (e.g., “Sam Altman”, “he”, “the CEO”) into a single canonical node, preventing graph fragmentation.
Knowledge Base Linking & Enrichment
Canonical entities are disambiguated against Wikidata / internal KBs. Matched entries inherit rich structured properties (aliases, types, geographic coordinates) automatically.
Graph Upsert & Indexing
Entities become nodes; relations become typed, weighted edges. Provenance edges link each fact back to its source chunk — enabling citation-grounded retrieval and auditability.
Agent Query Interface
Agents traverse the graph via Cypher / SPARQL, vector-search over node embeddings, or hybrid retrieval — combining structured graph paths with semantic similarity scores.
Knowledge Graph Anatomy
LLM Extraction Prompt Schema
# Entity + Relation extraction with structured output SYSTEM_PROMPT = """ You are a knowledge graph construction agent. Given a text passage, extract ALL entities and relations. Return ONLY valid JSON matching this schema: { "entities": [ { "id": "e1", "text": "Alan Turing", "type": "PERSON", "canonical": "Q7251", "confidence": 0.97 } ], "relations": [ { "subject": "e1", "predicate": "works_at", "object": "e2", "confidence": 0.91 } ] } """ async def extract_graph_from_chunk(chunk: str) -> dict: response = await llm.complete( system=SYSTEM_PROMPT, user=f"Extract entities and relations:\n\n{chunk}", temperature=0.0, # deterministic response_format="json_object" ) data = json.loads(response.text) return resolve_and_upsert(data) # dedup + write to graph
How Agents Use the Graph
Graph Traversal (Cypher)
Agents issue structured graph queries to follow multi-hop relation chains — e.g., “find all organisations connected to Person X within 2 hops.”
Vector + Graph Hybrid RAG
Semantic search over node embeddings seeds initial retrieval; graph traversal then expands context by following typed edges to related nodes.
Provenance & Citations
Every edge carries a source_chunk_id. Agents can cite the exact document and passage that grounded each stated fact — eliminating hallucination risk.
Incremental Updates
New documents trigger partial re-extraction. Conflict-detection merges contradictory facts and flags nodes with temporal version annotations for agent review.
Benefits for Agentic Systems
Precision Retrieval
Typed paths guarantee topically relevant context; irrelevant chunks are never retrieved, slashing noise and reducing token cost dramatically.
Compositional Reasoning
Multi-hop questions that stump flat-vector RAG systems are solved by following graph edges across conceptual distances without re-reading source text.
Auditable & Grounded
Every agent claim traces back to a source node, a source edge, and a source document. Compliance and explainability are first-class citizens.



