


Engineering Guide · Error Handling
Guardrails & Error Handling for Production AI Applications
A practitioner’s reference for building resilient, safe, and observable AI-powered systems — from input validation through graceful degradation to post-incident recovery.
Core Principles
Production AI applications fail differently than traditional software. Model outputs are probabilistic, latency is variable, and failure modes include subtle semantic errors that no exception handler can catch. Your error strategy must account for all layers.
Every error path should return a meaningful response to the user, never a blank screen or cryptic stack trace.
Exponential backoff, jitter, and budget-aware retry limits prevent thundering herds and runaway costs.
Sanitise input before the model, and validate output structure before it reaches the user or a downstream system.
Latency, token usage, refusals, and error rates should stream into your observability stack in real time.
Error Taxonomy
Categorising failures precisely lets you route them to the right handler. AI applications surface four distinct error families, each requiring a different response strategy.
| Class | Severity | Examples | Strategy |
|---|---|---|---|
| Infrastructure | Critical | API timeout, 5xx, network partition | Retry + circuit breaker |
| Rate limiting | High | 429 Too Many Requests, quota exceeded | Backoff + queue |
| Semantic | Medium | Hallucination, schema mismatch, refusal | Output validation + fallback prompt |
| Input policy | Low | Unsafe content, PII leak, prompt injection | Guardrail — reject before model |
Retry Patterns
Naive retries amplify traffic under failure. The gold standard for AI APIs combines exponential backoff with full jitter — spreading retries across time to prevent synchronised bursts.
async function retryWithBackoff<T>(
fn: () => Promise<T>,
opts: { maxAttempts: number; baseDelayMs: number }
): Promise<T> {
let attempt = 0;
while (attempt < opts.maxAttempts) {
try {
return await fn();
} catch (err) {
const isRetryable = isRetryableError(err);
const isLast = attempt === opts.maxAttempts - 1;
if (!isRetryable || isLast) throw err;
// Exponential backoff with full jitter
const cap = opts.baseDelayMs * 2 ** attempt;
const delay = Math.random() * cap;
await sleep(delay);
attempt++;
}
}
throw new Error("Max retry attempts reached");
}
function isRetryableError(err: unknown): boolean {
if (err instanceof APIError) {
return [429, 500, 502, 503, 504].includes(err.status);
}
return err instanceof NetworkError;
}Always wrap your retry loop in a token-budget or cost-budget check. Retrying a 50k-token prompt 5 times costs 250k tokens — set hard spending limits before entering the retry loop.
Input Validation
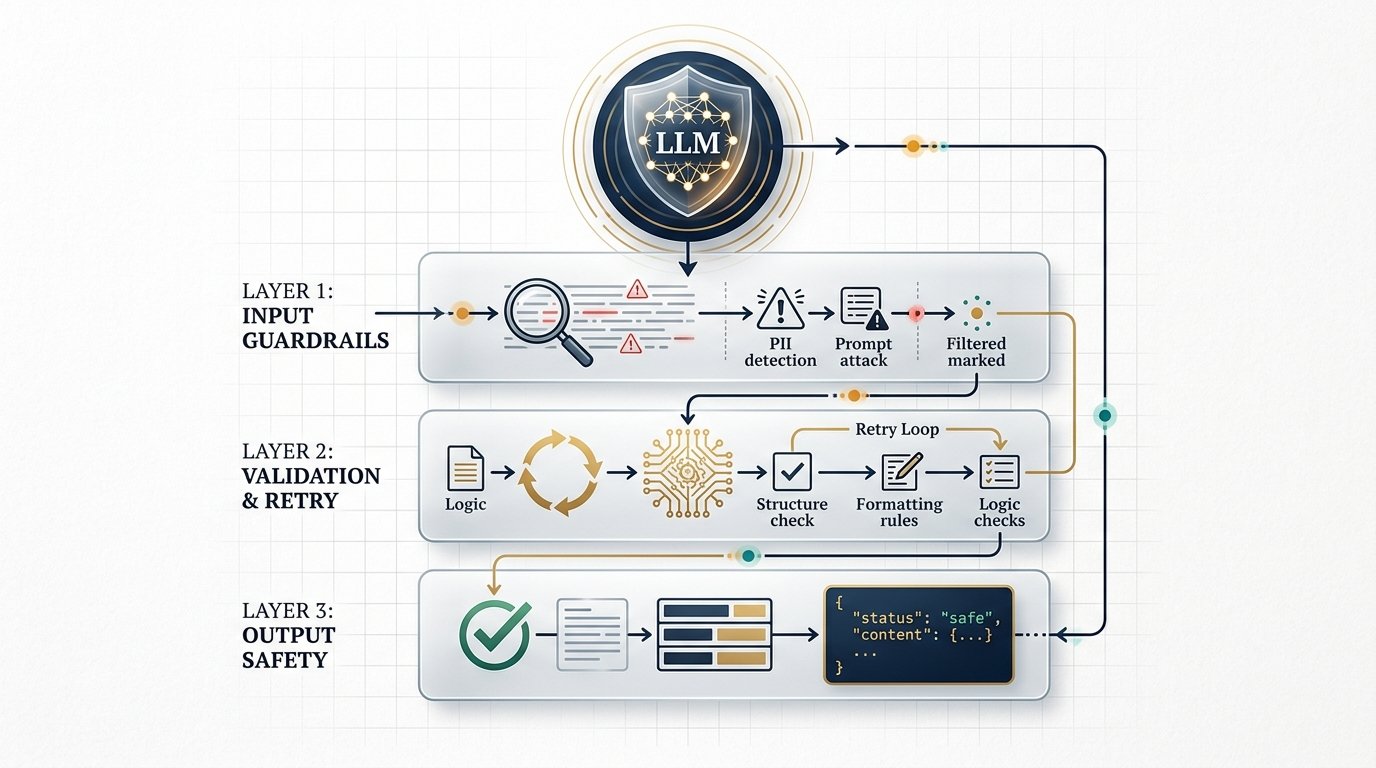
The cheapest error to handle is the one you prevent from reaching the model. Every input should pass through a validation pipeline before a single token is spent.
Enforce request shape — type, length limits, required fields. Reject malformed inputs with HTTP 400 before any model call.
Scan for emails, SSNs, credit cards, and phone numbers. Redact or pseudonymise before the prompt is assembled.
Flag attempts to override system instructions — “ignore previous instructions”, role-play escapes, delimiter manipulation.
Estimate prompt tokens before calling the API. Reject or truncate inputs that would breach context limits or cost thresholds.
Run a fast classifier or keyword filter for clearly policy-violating content before spending on a full model call.
The Guardrails Layer
Guardrails are your application’s immune system. They sit between raw user input and the model, and between the model and your downstream systems. A well-designed guardrail layer is symmetric — it filters both ingress and egress.
“A guardrail that can be bypassed by rephrasing the request is not a guardrail — it’s a speed bump. Design for adversarial inputs from day one.”
Output guardrails
After the model responds, validate the output before surfacing it to the user or invoking any tool calls embedded in the response.
from pydantic import BaseModel, ValidationError
from typing import Literal
class StructuredResponse(BaseModel):
action: Literal["search", "summarise", "answer"]
confidence: float # must be 0.0 – 1.0
content: str
citations: list[str] = []
def parse_and_guard(raw_output: str) -> StructuredResponse | None:
try:
data = json.loads(raw_output)
resp = StructuredResponse(**data)
# Post-parse semantic checks
if resp.confidence < 0.4:
log_low_confidence(resp)
return None # trigger fallback
if contains_pii(resp.content):
resp.content = redact(resp.content)
return resp
except (ValidationError, JSONDecodeError) as e:
log_parse_error(e, raw_output)
return NoneAlways define a structured output schema and instruct the model to adhere to it. JSON mode or tool-use structured outputs reduce parse failures by 60–80% compared to free-form text extraction.
If your application uses tool-calling or function-calling, never execute a model-generated tool call without validating the function name against an allowlist and sanitising all arguments. Treat tool calls as untrusted user input.
Circuit Breakers
When a downstream service is degraded, continuing to send traffic amplifies the failure. A circuit breaker detects sustained failure and opens, routing requests to a fallback until the service recovers.
type State = "CLOSED" | "OPEN" | "HALF_OPEN";
class CircuitBreaker {
private state: State = "CLOSED";
private failures = 0;
private lastFailureTime?: number;
constructor(
private threshold = 5, // failures before opening
private timeout = 60_000 // ms before half-open probe
) {}
async execute<T>(fn: () => Promise<T>, fallback: () => T): Promise<T> {
if (this.state === "OPEN") {
const elapsed = Date.now() - (this.lastFailureTime ?? 0);
if (elapsed < this.timeout) return fallback();
this.state = "HALF_OPEN"; // probe with next request
}
try {
const result = await fn();
this.onSuccess();
return result;
} catch (err) {
this.onFailure();
return fallback();
}
}
private onSuccess() { this.failures = 0; this.state = "CLOSED"; }
private onFailure() {
this.lastFailureTime = Date.now();
if (++this.failures >= this.threshold) this.state = "OPEN";
}
}Design a tiered fallback: (1) retry same model → (2) smaller/cheaper model → (3) cached response → (4) static safe response. Each tier should degrade gracefully, never crash.
Observability
You cannot improve what you cannot see. Every LLM call should emit structured telemetry covering latency, token consumption, cache status, and guardrail outcomes.
from dataclasses import dataclass, field
import time, uuid
@dataclass
class LLMSpan:
trace_id: str = field(default_factory=lambda: str(uuid.uuid4()))
model: str = ""
prompt_tokens: int = 0
output_tokens: int = 0
latency_ms: float = 0.0
cached: bool = False
error_type: str | None = None
guardrail_hit: str | None = None
def traced_completion(client, **kwargs) -> tuple:
span = LLMSpan(model=kwargs["model"])
t0 = time.perf_counter()
try:
response = client.messages.create(**kwargs)
span.prompt_tokens = response.usage.input_tokens
span.output_tokens = response.usage.output_tokens
span.cached = response.usage.cache_read_input_tokens > 0
return response, span
except Exception as e:
span.error_type = type(e).__name__
raise
finally:
span.latency_ms = (time.perf_counter() - t0) * 1000
emit_span(span) # → your telemetry sinkKey metrics to track
- P50 / P95 / P99 latency — segmented by model and prompt template
- Token spend rate — prompt vs. completion, with daily budget alerts
- Error rate by category — infra errors vs. policy refusals vs. parse failures
- Guardrail hit rate — which rules trigger most, and on what inputs
- Cache hit ratio — prompt caching effectiveness across your workload
- Fallback activation rate — how often circuit breakers open
Production Launch Checklist
Before shipping a new AI feature to production, verify every item below. This is a minimum bar — not a ceiling.
Input & validation
- Request schema validated with 400-level rejection on malformed input
- PII detection and redaction pipeline active
- Prompt injection patterns covered by integration tests
- Token budget enforced — inputs truncated or rejected above limit
Resilience
- Exponential backoff with jitter on all API calls
- Circuit breaker configured with tested fallback path
- Timeout set explicitly — never rely on the SDK default
- Graceful degradation message copy written and tested
Output & safety
- Structured output schema with Pydantic / Zod validation
- Tool-call allowlist and argument sanitisation in place
- Low-confidence responses route to human review or fallback
- Output PII redaction symmetric with input redaction
Observability
- Structured spans emitted for every LLM call
- Latency and token-spend dashboards live in your ops console
- Alerts configured for error rate > 2% or latency P95 > threshold
- Guardrail hit-rate dashboard reviewed weekly
Every item above is checked, you can kill the model API and the application returns a graceful degraded experience, and your on-call runbook covers the top 5 failure scenarios with step-by-step resolution guides.