

Bestseller #3

- [Long-Lasting] Each towel is designed to withstand hundreds of washes without fraying or losing its effectiveness. The t…
- [Premium, Lint-Free & Scratch-Free] Made from high-quality microfiber fabric, these towels are soft, lint-free, and scra…
- [Tear-Away Convenience & Easy to Use] KitchLife Microfiber towel rolls feature a unique tear-away design with 20 sheets …
₹199
AI Expert Guide
Semantic Search & Retrieval Strategies
A complete reference for building intelligent, meaning-aware search systems — from embeddings to hybrid pipelines and reranking.
Dense Retrieval
RAG Pipelines
Vector Databases
Hybrid Search
Reranking
Embeddings
Foundation
What is semantic search?
Unlike keyword search that matches exact tokens, semantic search understands meaning. A query for “heart attack symptoms” also returns results about “myocardial infarction” — because the system understands intent, not just words.
Keyword (Lexical)
Exact token matching. Fast, transparent, no training needed. Fails on synonyms, paraphrases, and intent mismatch.
Semantic (Dense)
Embedding-based similarity. Understands meaning, handles paraphrasing. Requires an encoder model and vector index.
Hybrid
Combines both signals via reciprocal rank fusion or weighted scoring. Best of both worlds for production use.
Reranking
A cross-encoder scores query–document pairs for precision. Applied after retrieval to reorder top-k candidates.
Core Pipeline
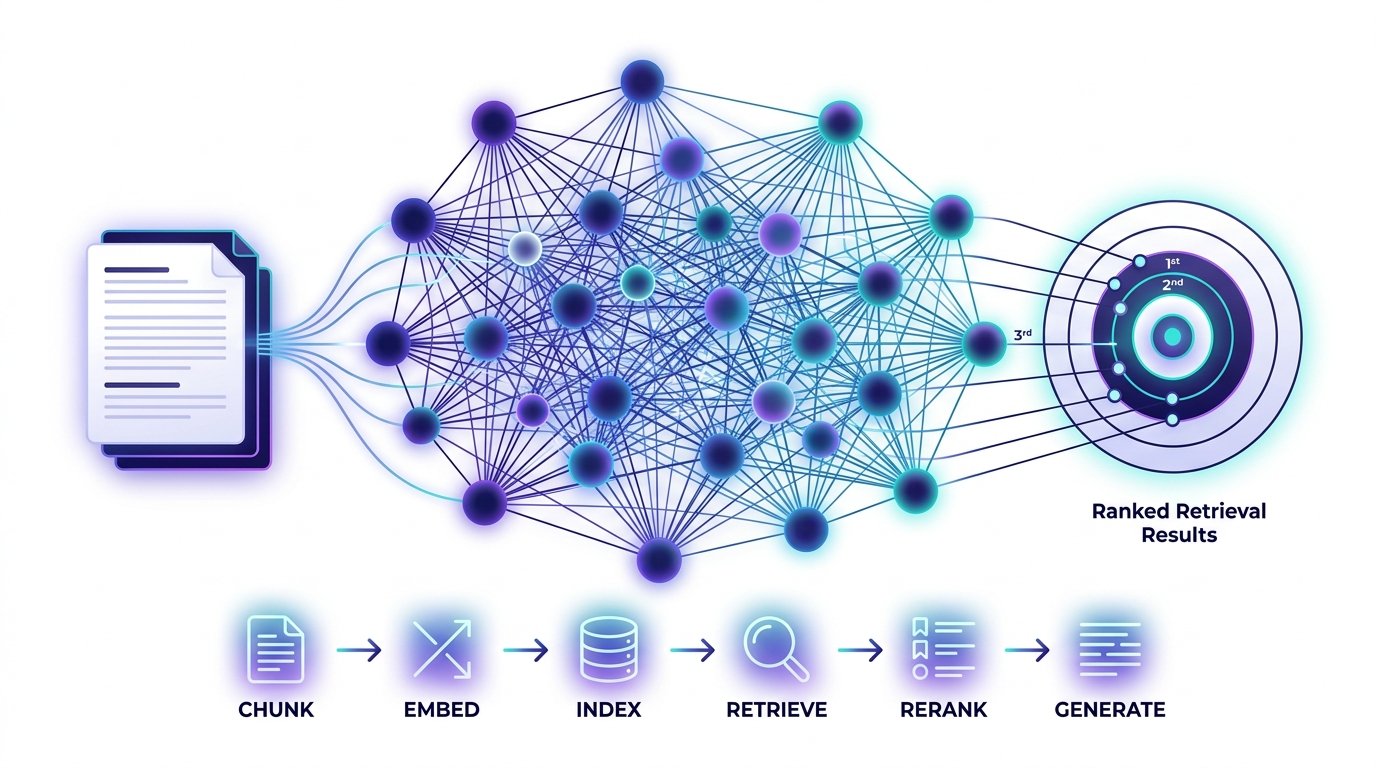
End-to-end retrieval flow
Every production semantic search system follows a common pipeline. Each stage has distinct responsibilities and optimization levers.
📥 Raw Documents
→
✂️ Chunking
→
🔢 Embed
→
🗄️ Vector Store
→
🔍 ANN Search
→
🎯 Rerank
→
💬 Generate
Pro tip: The biggest retrieval gains come from chunking strategy and embedding model choice — not from the vector database. Invest here first before optimizing infrastructure.
Retrieval Strategies
Choosing the right approach
Each strategy trades off precision, recall, latency, and engineering complexity. Match the strategy to your use case.
Dense
Bi-encoder retrieval
Encode query and documents independently. Inner product or cosine similarity at inference. Scales to billions of docs with ANN indexes (FAISS, HNSW).
Sparse
BM25 / TF-IDF
Classic inverted index. Excellent for exact match, IDs, codes, and rare terminology. Zero inference cost. Use Elasticsearch or Vespa.
Hybrid
RRF fusion
Reciprocal Rank Fusion merges dense + sparse ranked lists. No tuning needed. Consistently outperforms either alone with ~15–30% precision gain.
Advanced
HyDE & query expansion
Hypothetical Document Embeddings: generate a fake answer, embed it, retrieve similar docs. Dramatically improves zero-shot recall on open-domain tasks.
Chunking Strategies
How you split matters most
Poor chunking is the #1 cause of retrieval failure. The chunk must be semantically coherent and sized for your embedding model’s context window.
Fixed-size
Naive split by N tokens with overlap. Fast to implement, but breaks sentences and ideas. Baseline only.
Recursive character
Splits on \n\n → \n → space. Preserves paragraphs and sentences. Default choice for most text. Used by LangChain’s default splitter.
Semantic chunking
Embed sentences, split at cosine distance breakpoints. Topic-aware boundaries. More compute, much better retrieval quality.
Parent–child
Index small child chunks for precision, retrieve parent chunks for context. Best balance for RAG. Used in LlamaIndex’s auto-merging retriever.
Embedding Models
Choosing your encoder
1536
OpenAI text-embedding-3-large dims
768
BGE-large-en dims
8192
Max tokens (E5-mistral)
64.6
MTEB avg score (GTE-Qwen)
| Model | Best for | Open source | Long context |
|---|---|---|---|
| OpenAI text-embedding-3 | General purpose, fast API | No | No (8k) |
| BGE-M3 | Multilingual, hybrid-ready | Yes | 8192 tokens |
| E5-mistral-7b | Top MTEB, complex queries | Yes | 32k tokens |
| Cohere embed-v3 | Domain-specific, int8 quant | No | 512 tokens |
| GTE-Qwen2-7B | SOTA open, multilingual | Yes | 32k tokens |
Reranking
Precision after retrieval
Retrieve top-100 candidates fast with ANN, then rerank top-100 with a cross-encoder to surface the best 5–10. Cross-encoders attend jointly to query and document — far more accurate than bi-encoders.
# Example: two-stage retrieval with reranking
from sentence_transformers import CrossEncoder
reranker = CrossEncoder(“cross-encoder/ms-marco-MiniLM-L-6-v2”)
# Stage 1: fast ANN retrieval → top 100
candidates = vector_store.search(query_embedding, k=100)
# Stage 2: cross-encoder reranks top 100 → best 5
pairs = [(query, doc.text) for doc in candidates]
scores = reranker.predict(pairs)
top_docs = sorted(zip(scores, candidates), reverse=True)[:5]
Vector Databases
Indexing & storage options
Managed
Pinecone
Fully managed, serverless. Best for fast prototyping and teams without infra expertise. Strong metadata filtering.
Open Source
Qdrant / Weaviate
Self-hosted or cloud. Rich filtering, sparse+dense hybrid, payload indexing. Production-grade with full control.
SQL + Vector
pgvector
Postgres extension. Keep vectors next to relational data. No new infra. Best for teams already on PostgreSQL.
In-Memory
FAISS / Chroma
Local development and prototyping. FAISS is a library, not a server — wrap with LangChain/LlamaIndex for easy use.
Evaluation
Measuring retrieval quality
You cannot improve what you do not measure. Build an evaluation harness with labeled question–answer pairs before tuning any retrieval parameter.
Hit Rate @ k
Was the relevant document in the top-k results? Simplest metric. Target >85% hit rate @5.
MRR
Mean Reciprocal Rank. Rewards systems that put the best doc at rank 1, not just in top-k.
NDCG
Normalized Discounted Cumulative Gain. Gold standard for multi-relevant result ranking tasks.
Faithfulness / Answer relevance
RAG-specific: did the LLM answer stay grounded in retrieved docs? Use RAGAS or TruLens to automate scoring.
Bestseller #3
- [Long-Lasting] Each towel is designed to withstand hundreds of washes without fraying or losing its effectiveness. The t…
- [Premium, Lint-Free & Scratch-Free] Made from high-quality microfiber fabric, these towels are soft, lint-free, and scra…
- [Tear-Away Convenience & Easy to Use] KitchLife Microfiber towel rolls feature a unique tear-away design with 20 sheets …
₹199