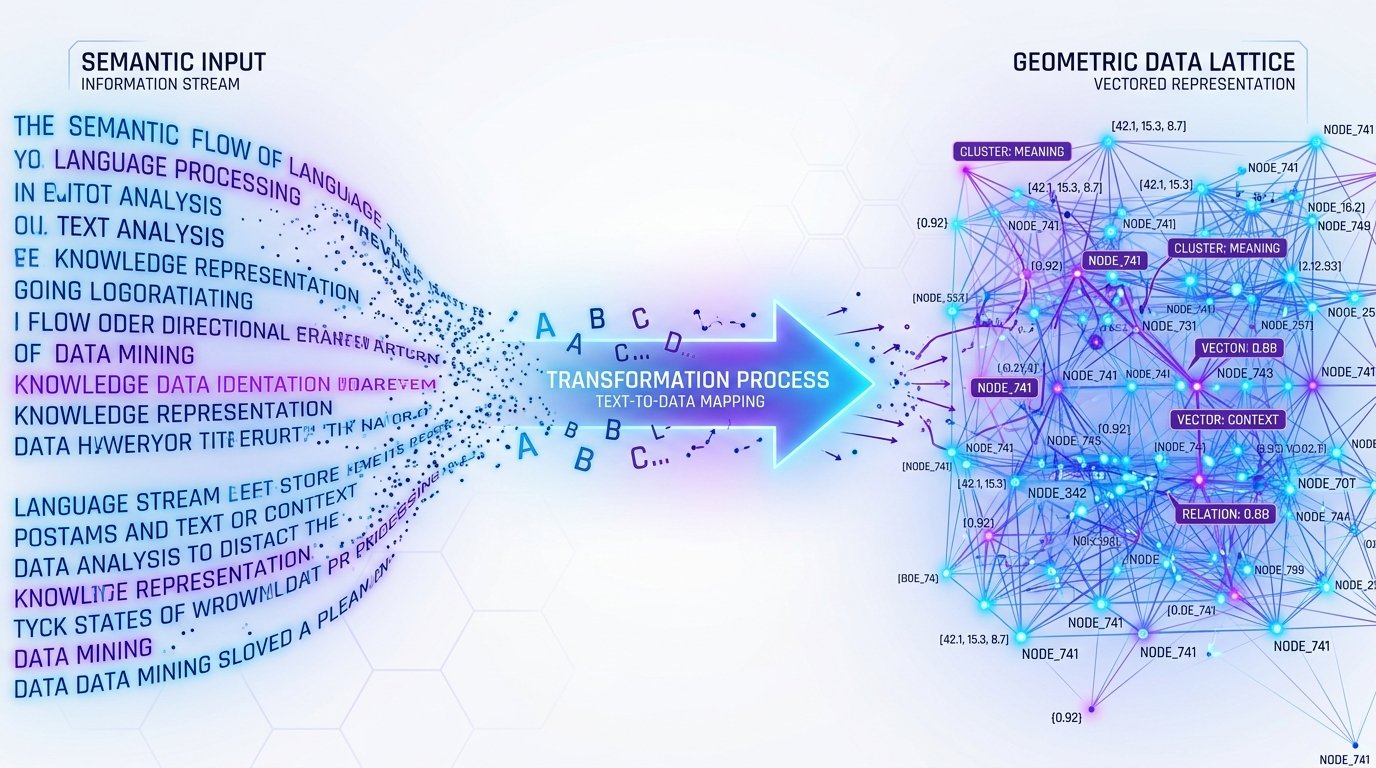



✨ Text Embeddings · Vectorize Intelligence
📐 From human language to high‑dimensional space
Embedding techniques convert raw text, reviews, or documents into dense numerical vectors — capturing semantic meaning, context, and relationships. Similar texts cluster together, enabling search, clustering, and AI understanding.
🧠 Core embedding techniques & architectures
🎯 Word-level (static)
Word2Vec GloVe FastText
Maps each word to a fixed vector, ignoring context. Great for traditional NLP, but fails on polysemy (e.g., “bank” vs “river bank”).
🧬 Contextual (dynamic)
BERT RoBERTa ELMo
Vectors change based on surrounding words. Attention mechanisms capture nuance, syntax, and long-range dependencies.
⚡ Sentence / document embeddings
Sentence‑BERT Instructor text-embedding-3
Optimized for semantic similarity, clustering, and retrieval. Maps entire paragraphs into a single vector, preserving meaning.
🌊 Multilingual & sparse
LaBSE Splade BM25 (lexical)
Cross-lingual understanding or sparse high-dim representations for efficient search.
🔍 Semantic proximity · cosine similarity in action
Two sentences, transformed into embedding vectors, yield a similarity score close to 1 if semantically related.
⚙️ Converting unstructured text → numerical data
🔹 Tokenization
Text is split into subword tokens (WordPiece, BPE). Each token maps to an initial ID.
🔹 Neural encoder
Transformer layers process tokens with positional encodings, self-attention, producing contextualized hidden states.
🔹 Pooling strategy
Common strategies: [CLS] token (BERT), mean pooling, or max pooling → final fixed‑dimension vector.
🔹 Normalization
Often L2 normalized so dot product equals cosine similarity, efficient for vector databases.
from sentence_transformers import SentenceTransformer
model = SentenceTransformer(‘all-MiniLM-L6-v2’)
sentences = [“AI is transforming the world.”, “Embeddings capture meaning.”]
embeddings = model.encode(sentences) # shape: (2, 384)
print(embeddings.shape) # → (2, 384)
🚀 Applications & modern embedding stacks
🗃️ Vector Databases
Pinecone, Milvus, Qdrant, Weaviate, FAISS, Chroma — store embeddings and enable ultra-fast ANN (approximate nearest neighbor) search at scale.
📈 Evaluation Metrics
Intrinsic: Spearman correlation with human similarity, Extrinsic: downstream task performance (Retrieval@k, MRR).
📌 Why embedding quality matters
Higher quality embeddings reduce the “semantic gap” — they capture idioms, paraphrases, and even cultural nuances. The current SOTA models (Voyage, Cohere Embed v3, OpenAI text-embedding-3-large) achieve MTEB benchmark scores > 64 for retrieval tasks.