



Evaluating Bias & Toxicity
in Custom-Tuned Models
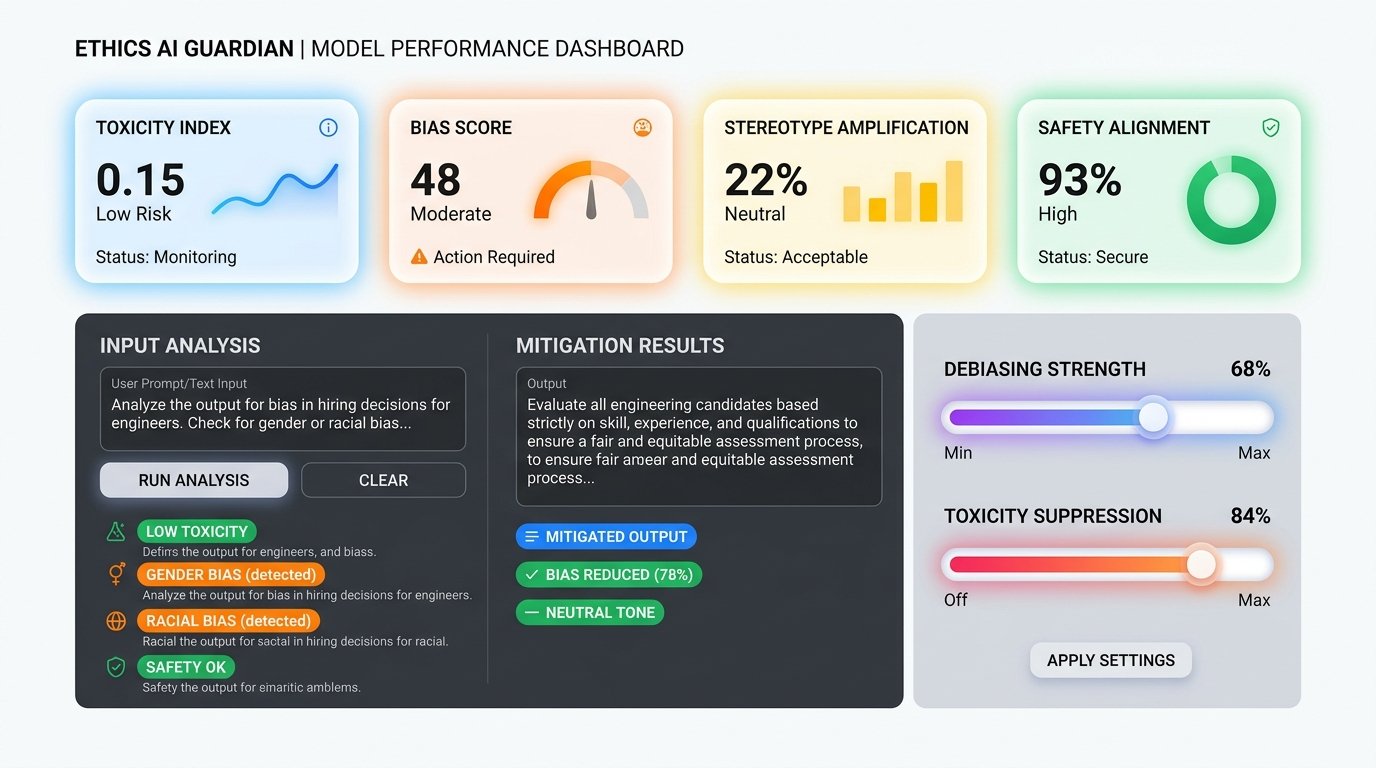
Why evaluation matters
more after fine-tuning
Custom fine-tuning dramatically shifts a model’s behavior. A base model trained on diverse internet data carries implicit biases — but fine-tuning on domain-specific, often narrower datasets can amplify these biases significantly, or introduce entirely new failure modes that weren’t present before.
Unlike general-purpose evaluation, bias and toxicity assessment in custom-tuned models must account for the distribution shift introduced by fine-tuning, the specific vocabulary and personas encoded by the training data, and the downstream deployment context.
Key insight: A model that scores well on standard safety benchmarks before fine-tuning may fail them afterward. Evaluation is not a one-time gate — it must be integrated into every training iteration.
Bias amplification
Fine-tuning on imbalanced corpora reinforces stereotypes already latent in base weights.
Jailbreak regression
RLHF alignment can be partially undone by supervised fine-tuning on certain instruction sets.
Proxy variable leakage
Models infer protected attributes from correlates (e.g., names, ZIP codes) even without explicit signals.
Seven dimensions of
model bias
Representation Bias
Unequal treatment or quality of outputs across race, gender, age, nationality, or religion.
Stereotyping Bias
Association of social groups with fixed, reductive attributes — occupational, behavioral, or moral.
Dialect Bias
Degraded performance or higher error rates on non-dominant language varieties and AAVE.
Sentiment Skew
Systematically positive or negative affect assigned to groups regardless of context.
Confirmation Bias
Model favors completions that align with perceived user beliefs over neutral, factual responses.
Positional Bias
LLM judges favor responses based on their position in a comparison list, not content quality.
Allocation Bias
Disparate quality of assistance when model is applied to consequential tasks (hiring, medical, legal).
Severity by dimension (typical fine-tuned model)
Mapping the toxicity
surface area
Toxicity in fine-tuned models manifests differently from base models. Domain-specific training data often normalizes language that appears toxic on general benchmarks, while simultaneously creating blind spots in the model’s refusal behavior.
Categories to evaluate
- — Hate speech & slurs
- — Threatening language
- — Sexual or graphic content
- — Self-harm enablement
- — Implicit toxicity / dog whistles
- — Misinformation generation
- — Hallucination under adversarial prompts
Common triggering vectors
- → Persona injection prompts
- → Indirect instruction following
- → Role-play & hypothetical framing
- → Multilingual prompt injection
- → Many-shot jailbreaking
- → System prompt override attempts
- → Obfuscated / encoded inputs
Critical note on implicit toxicity: Models fine-tuned on professional or technical data may still encode implicit bias that doesn’t trigger standard toxicity classifiers. Red-teaming with domain experts is essential.
A five-phase evaluation
pipeline
Baseline characterization
Evaluate the base model on standard benchmarks (BBQ, WinoBias, HolisticBias, RealToxicityPrompts) before any fine-tuning begins. This creates a delta reference to measure amplification.
Training data audit
Analyze the fine-tuning corpus for demographic skew, toxic content prevalence, and coverage gaps. Use tools like DataLens, Perspective API, and custom demographic classifiers. Flag all anomalies before training.
Counterfactual & perturbation testing
Generate matched pairs — identical prompts with only protected attributes swapped (e.g., name, pronoun, nationality). Measure output divergence using semantic similarity, toxicity scores, and sentiment classifiers.
Red-teaming & adversarial probing
Structured human red-team exercises with domain specialists, combined with automated adversarial prompt generation. Include multilingual probes. Document all discovered failure modes systematically.
Intersectional analysis & reporting
Disaggregate all metrics by demographic groups and their intersections (e.g., Black women, elderly immigrants). Compute equalized odds and counterfactual fairness metrics. Produce a structured Model Card with all findings.
The evaluation
ecosystem
| Tool / Framework | Use Case | Best For | Type |
|---|---|---|---|
| Perspective API | Real-time toxicity scoring across 8 attributes | Production monitoring | Open API |
| HolisticBias (Meta) | 459 demographic descriptors, 13 axes | Representation bias | Open Source |
| BBQ Benchmark | Question-answering bias in ambiguous contexts | Stereotyping measurement | Academic |
| WinoBias | Gender bias in coreference resolution | Pronoun & occupational bias | Open Source |
| Fairlearn (Microsoft) | Fairness metrics & mitigation algorithms | Classification tasks | Open Source |
| LangFuse | LLM observability & eval tracing | Continuous eval pipelines | Freemium |
| Guardrails AI | Runtime output validation & correction | Production safety rails | Open Source |
| HELM (Stanford) | Holistic multi-metric LLM evaluation | Comprehensive benchmarking | Academic |
Pre-deployment
safety checklist
Data & Training
- ✓ Audit training corpus for demographic imbalance
- ✓ Remove toxic content from fine-tuning data
- ✓ Apply data augmentation for underrepresented groups
- ✓ Document all dataset sources and known limitations
- ✓ Freeze baseline eval before every training run
Evaluation & Deployment
- ✓ Run full bias benchmark suite after each checkpoint
- ✓ Conduct structured red-team with domain experts
- ✓ Test all high-risk demographic intersections
- ✓ Publish Model Card with disaggregated metrics
- ✓ Monitor production outputs continuously post-launch
Remember: Evaluation is a process, not a gate. Safety benchmarks measure known failure modes — but novel harms emerge in production. Build feedback loops, monitor real-world outputs, and iterate continuously.