


Deep Learning · Language Models · Training Methods
How LLMs
Learn to
Think
Pre-Training
Learning the shape of language at scale
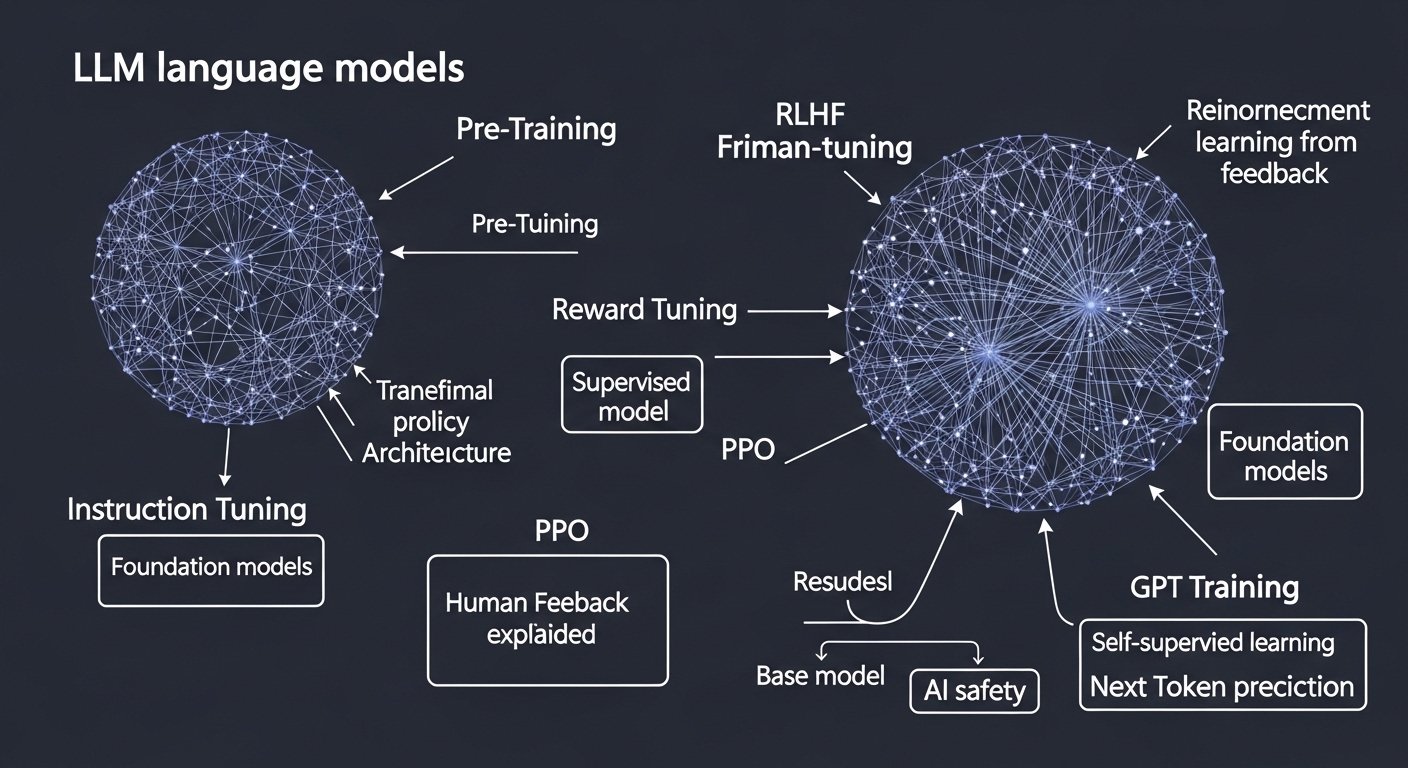
Pre-training is the first and most computationally intensive stage. A neural network — typically a Transformer architecture — is exposed to trillions of tokens drawn from the internet, books, and curated corpora. The model learns by a simple self-supervised objective: predict the next token.
“The model is never told what language is. It discovers grammar, facts, reasoning, and style purely from statistical co-occurrence — billions of times over.”
Through gradient descent, the network adjusts hundreds of billions of parameters to minimise prediction error. Over time it internalises syntax, factual associations, code patterns, and even rudimentary logic — all as a byproduct of next-token prediction.
Self-supervised objective
No human labels needed. The text itself provides the training signal via next-token prediction.
Transformer architecture
Attention mechanisms let each token attend to all previous tokens, capturing long-range dependencies.
Emergent capabilities
At sufficient scale, abilities like in-context learning and chain-of-thought reasoning emerge unpredictably.
Base model output
The result is a powerful but “raw” model — fluent, knowledgeable, yet not instruction-following.
Fine-Tuning
Teaching the model to follow instructions
The pre-trained base model is a world-class language predictor, but it does not know how to help a user. Fine-tuning bridges this gap by continuing training on a much smaller, curated dataset of (instruction, ideal response) pairs — often called Supervised Fine-Tuning (SFT).
Human annotators craft thousands of examples demonstrating good assistant behaviour: answering questions accurately, following formatting requests, refusing harmful prompts politely. The model is then trained on these examples in the usual supervised fashion — compute loss against the ideal response, backpropagate, update weights.
“Fine-tuning does not teach the model new facts. It reshapes how the model uses the knowledge it already has — pivoting from prediction to conversation.”
Instruction datasets
Carefully curated pairs of prompts and ideal completions, covering diverse tasks and domains.
Supervised learning
Standard cross-entropy loss against target responses. Small dataset, many fewer gradient steps than pre-training.
Format & style
The model learns conversational structure: how to open, acknowledge, reason, and conclude an answer.
Domain adaptation
Fine-tuning can also specialise a model for medicine, law, coding, or any narrow vertical.
RLHF
Reinforcement Learning from Human Feedback
Even after SFT, the model may produce responses that are subtly unhelpful, verbose, or unsafe. RLHF addresses this by using human preferences — not just examples — as the training signal, via a reinforcement learning loop.
The key insight is that it is easier for humans to compare two responses than to write an ideal one from scratch. Annotators rank pairs of outputs; these rankings train a separate reward model that learns to score responses as humans would. The policy (LLM) is then optimised via Proximal Policy Optimisation (PPO) to maximise the reward model’s score.
“RLHF turns implicit human taste into an explicit numerical signal — and then uses that signal to nudge billions of parameters toward helpfulness, harmlessness, and honesty.”
Reward modelling
A separate model trained on preference pairs. It predicts a scalar score for any (prompt, response) pair.
PPO algorithm
Proximal Policy Optimisation keeps updates small, preventing the LLM from “hacking” the reward model catastrophically.
KL-divergence penalty
A regularisation term keeps the RLHF model close to the SFT base, preserving knowledge and preventing degeneration.
Constitutional AI & DPO
Modern variants like Anthropic’s CAI and Direct Preference Optimisation simplify or replace the RL loop entirely.
Comparing the Stages
Side-by-side at a glance
| Dimension | Pre-Training | Fine-Tuning | RLHF |
|---|---|---|---|
| Goal | General language understanding | Instruction following | Preference alignment |
| Data | Web-scale unlabelled text | Curated (prompt, response) pairs | Human preference rankings |
| Supervision | Self-supervised | Supervised (teacher-forced) | Reinforcement learning |
| Compute | Enormous (weeks on thousands of GPUs) | Moderate (hours–days) | Moderate–high (complex loop) |
| Data size | Trillions of tokens | Thousands–millions of examples | Tens–hundreds of thousands of comparisons |
| Key challenge | Scale, data quality, infrastructure | Prompt diversity, annotation quality | Reward hacking, annotation bias |