books Somish Saipar June 6, 2026 No Comments LLM Fine-Tuning & Optimization: Instruction Tuning, LoRA, RLHF & Prompt Strategies
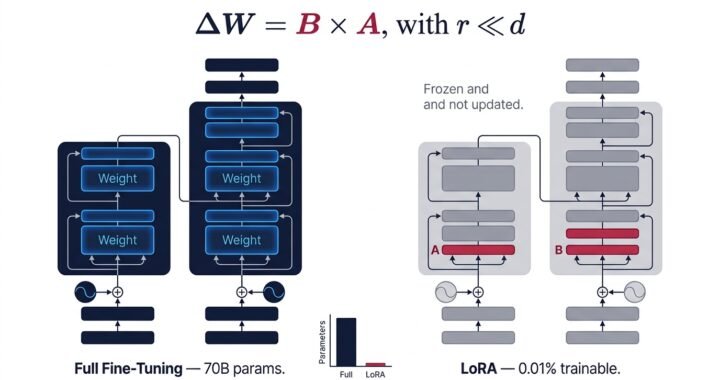
Somish Saipar April 20, 2026 No Comments LoRA & PEFT Explained: How to Fine-Tune Large Language Models with 0.01% of Parameters (2024 Guide)
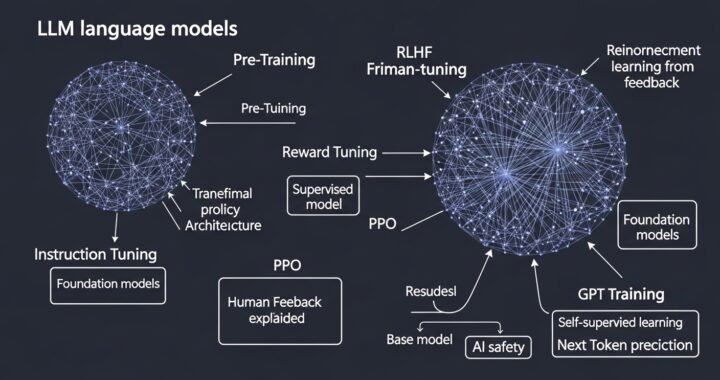
Somish Saipar April 11, 2026 No Comments How LLMs Learn to Think: Pre-Training, Fine-Tuning & RLHF Explained
Somish Saipar March 4, 2026 No Comments Fine-Tuning vs. Prompt Engineering: Which AI Strategy Should You Choose?