


PEFT · LoRA · QLoRA
Parameter-efficient fine-tuning methods that adapt large language models to new tasks — without retraining billions of weights. A complete technical reference.
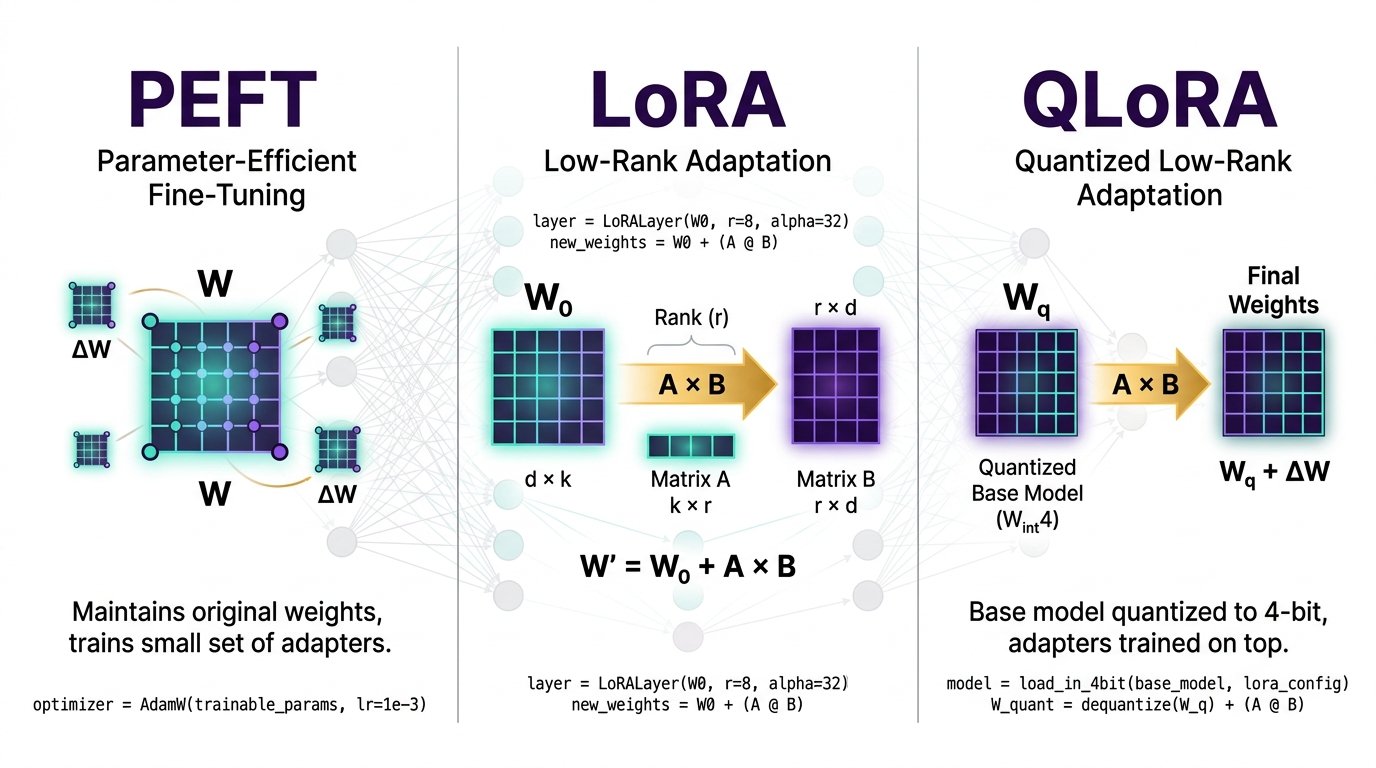
Parameter-Efficient Fine-Tuning
The umbrella framework — a family of techniques to adapt LLMs by training only a small subset of parameters.
- Freezes pre-trained weights; only small modules learn
- Prevents catastrophic forgetting of general knowledge
- Multiple task adapters share one base model
- Supported natively by HuggingFace
peftlibrary - Enables fine-tuning on consumer-grade GPUs
Low-Rank Adaptation
Decomposes weight updates into two small matrices — elegant math that slashes trainable parameters dramatically.
- ΔW = A·B where A ∈ Rd×r, B ∈ Rr×k, r ≪ d
- Applied to attention weight matrices (Q, K, V, O)
- Weights can be merged at inference — no latency cost
- Rank
rcontrols capacity vs efficiency trade-off - Alpha
αscales the learned update magnitude
Quantized LoRA
Combines 4-bit quantization with LoRA adapters — fine-tune a 65B model on a single 48 GB GPU.
- 4-bit NormalFloat (NF4) preserves weight distribution
- Double quantization compresses quant constants further
- Paged optimizers offload optimizer states to CPU RAM
- Adapters computed in BF16 for numerical stability
- Enables 70B-class models on hobbyist hardware
PEFT, LoRA, QLoRA: A formal guide to efficient fine-tuning of large models
The growth of large language models (LLMs) intensified the need for efficient fine-tuning approaches. Parameter-efficient fine-tuning (PEFT) techniques, such as Low-Rank Adaptation (LoRA) andized LoRA (QLRA), enable effective specialization of models with limited additional parameters and reduced computational requirements This provides a clear, ready-to-use overview and a practical tutorial for practitioners seeking to implement PEFT in real-world workflows## Definitions and concepts- PEFT (Parameter-Efficient Fine-T): framework for adapting pre-trained by updating only a small subset of parameters, while keeping the base model frozen or minimally altered.
- LoRA (Low-R Adaptation): A technique that injects train low-rank matrices into selected layers, enabling performance gains with small number of trainable parameters.
- QLoRA (Quantized LoRA): An extension of LoRA that employs quantization to further reduce memory usage, enabling fine-tuning on GPUs with limited memory.
- 4-bit and NF4ization: Quant schemes that lower numerical precision of weights to 4-bit representations (or NF formats) to decrease memory and bandwidth requirements during training and inference.
- Adapter tuning: PEFT approach adds small adapter modules between existing layers, training only those adapters while the main network.
- HuggingFace PEFT: A widely used library that provides implementations of PEFT methods (including LoRA,, and related utilities) for PyTorch-based models.
Why PEFT matters for LLMs
- Dram reduction in trainable parameters: Typically well below 1 of the base’s parameters.
- Memorable GPU savings:stantial reductions in memory footprint enable training on consumer-grade GPUs multi-GPU with lower hardware requirements.
- Faster: Lower training times per experiment, enabling rapid iteration and fine-tuning of multiple tasks.
- of general knowledge: PE methods catastrophic forgetting by keeping the base model stable while enabling task-specific specialization.
Key methods and how differ
- LoRA
- Concept: Injects low-rank trainable matrices into attention and/or feed networks.
- Benefit Large in trainable parameters with empirical performance across tasks.
- Typical configuration: Rankr) in the range of –64, with corresponding adjustments to rates regularization.
- Adapter
- Concept: Adds small trainable modules (adapters) within each transformer layer.
- Benefit: Flexible, modular approach compatible with many architectures.
- QLoRA and quantization
- Concept Combines LoRA with weight quantization (e.g., -bit, NF4) to further reduce memory usage.
- Benefit: Enables training models on GPUs with restricted memory while competitive accuracy.
- Other PEFT variants
- Prefix tuning, full adapters, or hybrid approaches that combine multiple modules for task adaptation.
Practical setup outline
- Choose the base model Select a pre-trained L appropriate for your, compatibility with the PEFT tooling (e.g., HuggingFace PEFT).
- Decide on the PEFT method: LoRA, adapters, or a. For memory-constrained environments, consider QLoRA 4-bit or NF4 quantization.
- Prepare data: Curate task-specific data with careful formattingprompt templates, instruction-following style evaluation metrics).
- Configure training: Set learning rates, batch sizes, gradient accumulation steps, and regularization. Determine the rank (r) for LoRA and identify target layers- Quantization strategy (if applicable): Choose 4-bit or NF4 quantization and select appropriate backends (e.g., bitsandbytes) that support chosen.
Training and evaluation: Monitor training loss, validation, and potential overfitting. on held-out data and error analysis. - Deployment considerations: Export adapters or LoRA weights and load onto the base model for inference, compatibility with serving infrastructure.
A tutorial: fineuning with LoRA (-level)
- dependencies (examples PyTorch and HuggingFace ecosystems):
- pip install transformers pe bitsandbytes
- Load the base and tokenizer:
- from transformers import AutoModelForCausal, AutoTokenizer
- model = AutoModelForCausalLM.from_pretrained(“base-model-name quantization_config=None)
- tokenizer = AutoTokenizer.from_pretrained(“-model”)
. Define LoRA configuration:
- from peft import LoraConfig, get_pe_model,Type – config = LoraConfig(
_type=TaskType.CAUS_L,
r=8 ora_alpha=32,
lora_dropout=.1
)
- Apply PEFT to the base model – model = getft_model(model config)
- Prepare dataset and collator:
Use a suitable dataset and collate function for causal language modeling or instruction-follow format. - Set training arguments and commence training:
- from transformers import Trainer TrainingArguments
-_args = TrainingArguments(…) - trainer = Trainer(model=model, args=training_args train_dataset=train_dataset, eval_dataset=valid_dataset)
- trainer.train7. Evaluate and save:
- trainer.evaluate()
- model.save_pretrained(“path-to-save-peft-model”)
- from transformers import Trainer TrainingArguments
- Inference with the fine-tuned model:
Generate responses by calling model.generate with appropriate prompts and decoding settings.
Note: employing quantization4-bit or4), ensure training framework and support the selected precision, and leverage optimized back such as bitsandbytes to manage memory efficiently.
Quantization considerations and practices
- Suitability Quant is particularly beneficial for very large models where memory is a primary constraint.
- trade: Lower precision can introduce small accuracy trade-offs; validate thoroughly on task-specific.
- Calibration: If required, calibration steps to quantization-induced errors.
- Hardware compatibility: Ensure GPUse.g with NVIDIA A100/A800-class capabilities and stacks support the chosen quantization format## Evaluation metrics and governance
- Task-specific metrics: Perplexity, accuracy,1, BLEU, or human evaluation, depending on task.
- Robustness checks: Test across diverse prompts and edge cases to stable behavior.
- Reproducibility: Document all hyperparameters, seeds, and data processing to enable repeatability.
- Safety and alignment: Monitor outputs for alignment policy and ethical guidelines; implement safeguards as needed.
Deployment and considerations
- Lightweight deployment PEFT weights are typically, enabling efficient distribution and updates.
- Version control: base and PEFT components separately to manage compatibility.
Monitoring: Implement continual evaluation to detect drift or in performance. - Scalability: Plan for updates as models evolve or as PEFT techniques emerge.
Common pitfalls and how to them
- Over-parameterization: unnecessarily large rank values; start with settings and scale as needed.
- Incompatible: that the PEFT method targets layers with the approach (e., attention and feed-forward modules for LoRA- leakage: Maintain strict separation between training evaluation data to obtain reliable metrics.
- Quant shocks: Validate thoroughly when introducing quant, for generation quality and token predictions.
resources
- HuggingFace PEFT documentation and tutorials- Research literature on LoRA and QLoRA methodologies
- Community forums practitioner blogs focusing on L fineuning and efficiency
This guide provides solid, actionable foundation for implementing parameter-efficient fine-tuning of large language models using LoRA, QLoRA, related techniques. It is suitable for researchers, engineers, and data scientists seeking to optimize AI model and deployment in resource-constrained environments.






