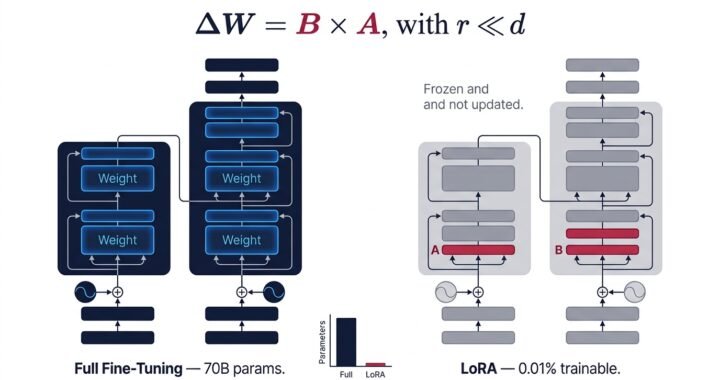
Somish Saipar April 20, 2026 No Comments LoRA & PEFT Explained: How to Fine-Tune Large Language Models with 0.01% of Parameters (2024 Guide)
Somish Saipar February 16, 2026 No Comments Hyperparameter Optimization Guide: Fine-Tune ML Models for Peak Performance | Step 7 Cheat Sheet 2026