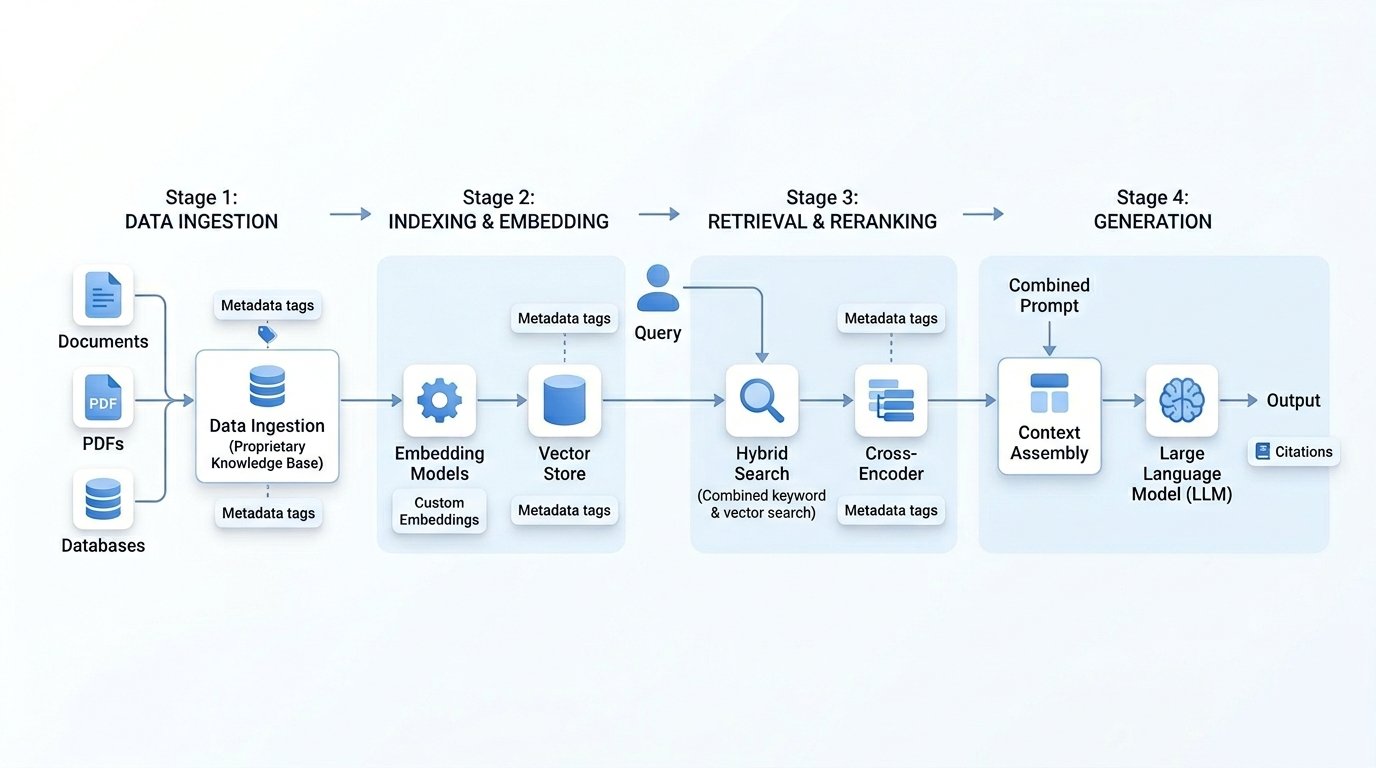




Architecture of a RAG Pipeline
Fixed lush background, seamless scroll.
📂 Sources
Internal PDFs, technical docs, proprietary databases, Confluence, private APIs, domain-specific XML/JSON.
✂️ Chunking & Cleaning
Semantic chunking (by headers, paragraph boundaries) to preserve domain context. Remove noise, PII redaction, metadata enrichment.
⚙️ Preprocessing
OCR for scanned docs, entity extraction (domain terms), normalize domain jargon, build document lineage.
🔢 Embedding Models
Domain‑fine‑tuned embeddings (e.g., Med‑BERT, FinBERT, or custom dense retrievers). Better semantic capture of proprietary terminology.
🗂️ Vector Store
Pinecone / Weaviate / Qdrant / FAISS with metadata filtering. Support for hybrid search (sparse + dense) & partition by domain categories.
🏷️ Metadata Index
Versioning, timestamps, source authority, department tags, access control levels for fine‑grained retrieval.
🎯 Query Encoder
Transform user query using same domain embedding model. Optional query rewriting / expansion with domain thesaurus.
📊 Hybrid Retrieval
Vector similarity + keyword BM25 + metadata filters. Retrieve top‑K candidates (K=15–30) for diversity.
⚖️ Reranking (Cross‑Encoder)
Domain‑specific cross‑encoder (e.g., MiniLM fine-tuned) to reorder chunks by semantic relevance, reduce hallucination.
🤖 LLM (Generator)
GPT‑4, Llama 3, Claude, or domain‑fine‑tuned model. Prompt includes retrieved chunks + system instruction enforcing domain adherence.
🧩 Context Assembly
Merge top reranked passages, truncate to fit context window. Include citations & source metadata for traceability.
✅ Guardrails & Verification
Domain validation, factual consistency check, hallucination detection, citation grounding. Optional human‑in‑the‑loop for high‑stakes.
🧬 Domain‑Specific Enrichment
Advanced RAG pipelines incorporate knowledge graphs, ontologies, and feedback loops. Fine‑tune retrievers on in‑domain query‑document pairs.
🏛️ Why domain‑specific RAG?
Generic RAG fails on private jargon, schemas, and compliance needs. Domain adaptation — custom embeddings, metadata filtering, and reranking — ensures factual, reliable answers from proprietary knowledge bases.
