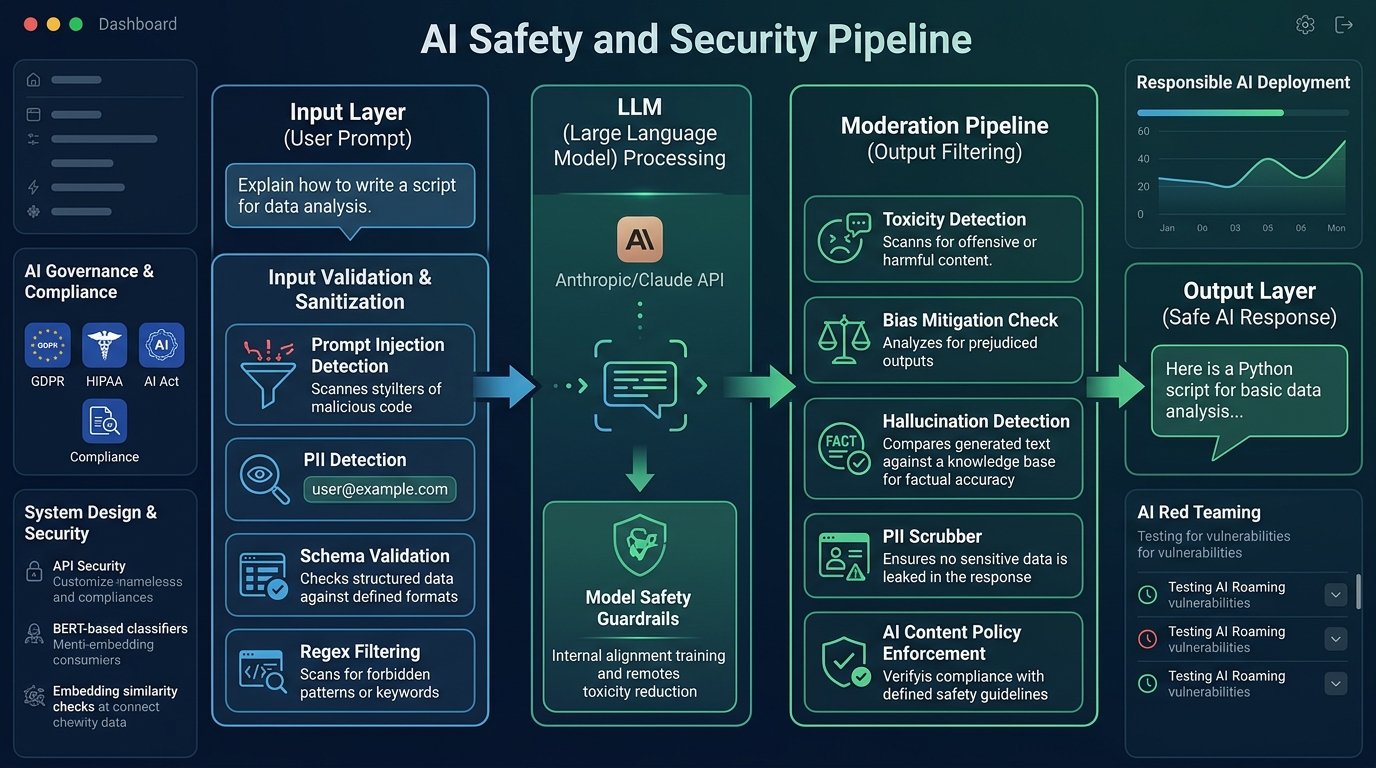





Implementing Input/Output
Validation & Moderation
A comprehensive technical guide to building robust validation pipelines and moderation filters for AI-powered systems — from prompt sanitization to response safety checks.
Why Validation & Moderation Matter
AI systems that accept natural language inputs are inherently vulnerable to adversarial prompts, hallucinations, and harmful output generation. A robust validation and moderation layer is the difference between a safe production deployment and a liability. These filters operate at two critical junctions: before the model processes a request, and before the model’s response reaches the end user.
Prompt Injection Defense
Block attempts to override system instructions or hijack model behavior via crafted inputs.
Harmful Content Prevention
Detect and block requests for violence, illegal activity, CSAM, or dangerous instructions.
Output Quality Assurance
Validate responses for factual coherence, format compliance, and policy adherence.
Regulatory Compliance
Ensure outputs meet GDPR, HIPAA, and AI Act requirements before delivery.
PII Detection & Redaction
Identify and mask personally identifiable information in both directions.
The Validation Pipeline
A complete I/O validation system operates as a layered pipeline. Each stage can independently reject, modify, or pass a request — providing defense in depth.
Each guard layer must be stateless, horizontally scalable, and add no more than 20–50ms per direction. Async logging should run out-of-band — never on the hot path.
Guarding the Input Layer
Input validation is your first and most important line of defense. It runs before any tokens are sent to the model, reducing both safety risk and inference cost.
Length & Schema Validation
Enforce structural constraints before any semantic analysis.
import re from dataclasses import dataclass from enum import Enum class ValidationResult(Enum): PASS = "pass" BLOCK = "block" TRANSFORM = "transform" @dataclass class InputValidator: max_tokens: int = 4096 min_tokens: int = 1 allowed_languages: list = None def validate(self, text: str) -> ValidationResult: # 1. Length check token_count = self.estimate_tokens(text) if token_count > self.max_tokens: return ValidationResult.BLOCK # 2. Injection pattern detection if self.detect_injection(text): return ValidationResult.BLOCK # 3. PII scan if self.contains_pii(text): return ValidationResult.TRANSFORM return ValidationResult.PASS def detect_injection(self, text: str) -> bool: patterns = [ r"ignore (all |previous )?instructions?", r"you are now (a|an) (?!assistant)", r"(system|developer) (prompt|message):", r"jailbreak|DAN mode|pretend you", ] return any(re.search(p, text, re.IGNORECASE) for p in patterns)
Prompt Injection Signals
- Instructions to “ignore”, “forget”, or “override” prior context
- Role-play framings that attempt to strip safety guidelines
- Base64 or Unicode-encoded hidden instructions
- Nested delimiters attempting to escape the system prompt boundary
- Requests to reveal the system prompt verbatim
- Indirect injection via retrieved documents (RAG attack surface)
Filtering the Output Layer
Even with strong input guards, models can still produce harmful, hallucinated, or policy-violating content. Output moderation intercepts the model’s response before delivery.
Output filters must handle streaming responses. Buffer enough tokens to make a confident classification before flushing to the client — typically 128–256 tokens. Flush prematurely and you lose the ability to retract harmful prefixes.
from anthropic import Anthropic import asyncio client = Anthropic() async def moderated_completion(user_input: str) -> str: # Stage 1: Input guard (classifier call) classification = await classify_input(user_input) if classification.risk_level == "HIGH": return refusal_message(classification.category) # Stage 2: LLM inference response = client.messages.create( model="claude-opus-4-5-20251001", max_tokens=1024, messages=[{"role": "user", "content": user_input}] ) raw_output = response.content[0].text # Stage 3: Output guard output_check = await scan_output(raw_output) if output_check.contains_pii: raw_output = redact_pii(raw_output) if output_check.policy_violation: raise PolicyViolationError(output_check.reason) return raw_output
Types of Moderation Filters
| Filter Type | Direction | Method | Latency | Accuracy |
|---|---|---|---|---|
| Regex / Rule-based | In Out | Pattern matching | <1ms | Medium |
| Classifier model | In Out | Fine-tuned BERT/DeBERTa | 5–20ms | High |
| Embedding similarity | In | Vector cosine vs. known attacks | 10–30ms | High |
| LLM-as-judge | Out | Secondary model evaluation | 200–800ms | Very High |
| PII detection (NER) | In Out | Named entity recognition | 15–40ms | High |
| Toxicity scorer | In Out | Perspective API / custom model | 20–50ms | High |
| Hallucination checker | Out | Entailment / RAG grounding | 100–500ms | Medium |
| Schema validator | Out | JSON/Pydantic parsing | <1ms | Exact |
Risk Classification Matrix
Route requests to the appropriate filter chain based on their risk profile. Higher-risk inputs get more expensive but more accurate guards.
Building the Moderation Layer
A production-grade moderation system should be an independent microservice with its own rate limits, circuit breakers, and fallback behavior. Never let a guard failure block the primary user flow — fail open with logging, then tighten over time.
from dataclasses import dataclass, field from typing import List, Optional import time @dataclass class ModerationPipeline: stages: List = field(default_factory=list) fail_open: bool = True # Don't block on guard errors timeout_ms: int = 200 # Max guard chain latency def add_stage(self, guard, priority: int = 0): self.stages.append((priority, guard)) self.stages.sort(key=lambda x: x[0]) # lowest priority runs first async def run(self, text: str) -> dict: start = time.monotonic() result = {"verdict": "pass", "triggered": [], "latency_ms": 0} for _, guard in self.stages: try: outcome = await guard.evaluate(text) if outcome.verdict == "block": result["verdict"] = "block" result["triggered"].append(guard.name) break # fail fast on first block except Exception as e: log_guard_error(guard.name, e) if not self.fail_open: result["verdict"] = "block" break result["latency_ms"] = round((time.monotonic() - start) * 1000, 1) return result
Production Best Practices
Red-team your own system
Before deployment, conduct adversarial testing. Use automated red-teaming tools to probe for bypass techniques — jailbreaks evolve rapidly and your filter patterns must be updated continuously.
Maintain a violation log
Every blocked request and flagged output should be logged with full context. This data is invaluable for improving classifier accuracy and understanding emerging attack patterns.
Tune thresholds by context
A consumer chatbot and a medical documentation tool have very different risk tolerances. Build your pipeline so that each deployment can configure sensitivity thresholds independently.
- Run input and output guards in parallel where possible to minimize latency
- Use a shadow mode (log but don’t block) when rolling out new filter rules
- Implement exponential backoff for users who repeatedly trigger content filters
- Version your filter rules and support rollback within minutes
- Monitor false positive rates — over-filtering degrades user experience critically
- Cache classifier results for identical or near-duplicate inputs
- Separate PII redaction from policy enforcement — different latency and accuracy profiles
- Test your filters against multilingual and code-switching inputs
The combined input + output guard overhead should stay below 80ms at p95. Profile each stage independently. Regex filters run in microseconds; LLM-as-judge should be reserved for asynchronous review queues, not the synchronous path.
