




Establishing Human-in-the-Loop Workflows for Critical Applications
A comprehensive framework for designing AI systems where human judgment remains integral — ensuring reliability, accountability, and trust in high-stakes environments.
What Is Human-in-the-Loop?
Human-in-the-Loop (HITL) is a design paradigm where human intelligence is woven into automated AI workflows at strategic checkpoints. Rather than relegating humans to passive observers, HITL systems treat human judgment as an active, decisive component — especially when consequences are significant, data is ambiguous, or ethical considerations are paramount.
Targeted Intervention
Humans intervene at precisely calibrated moments — when AI confidence drops, edge cases arise, or stakes exceed acceptable thresholds — rather than reviewing every decision.
Continuous Learning Loop
Each human decision feeds back into the model, enabling the AI to improve over time. HITL is not a static safety net — it is a dynamic training mechanism.
Accountability by Design
Embedding human decision points creates clear audit trails, ensuring that critical outcomes can be traced, justified, and challenged by appropriate stakeholders.
Risk Stratification
Decisions are automatically routed based on risk score, complexity, and context — directing the highest-stakes cases to the most qualified human reviewers.
Collaborative Intelligence
The best outcomes emerge not from AI alone or humans alone, but from structured collaboration that leverages the unique strengths of both.
Measurable Oversight
HITL workflows generate rich metrics: review rates, override frequency, latency, and error rates — enabling continuous refinement of the human-AI boundary.
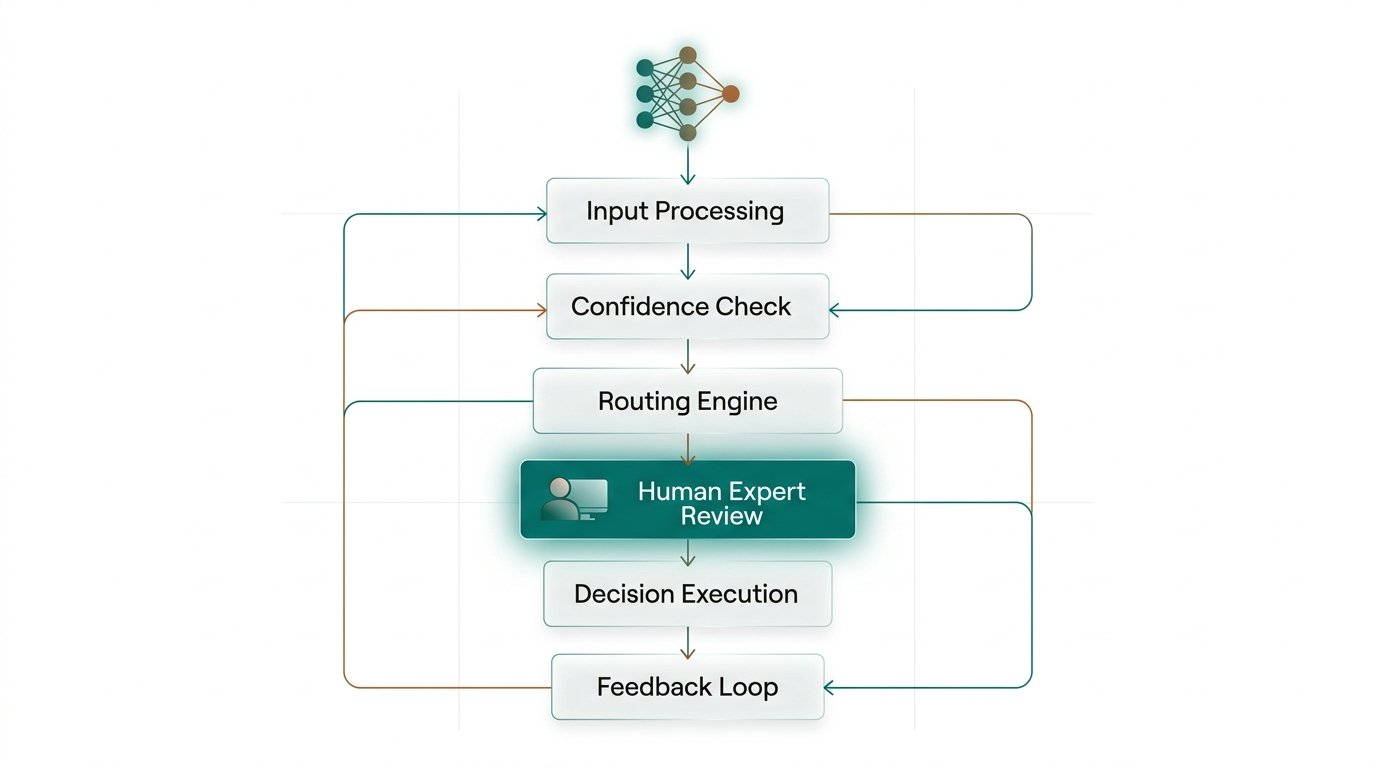
The Six-Stage Workflow
A production-ready HITL system is more than a review queue. It is a carefully engineered pipeline that balances automation efficiency with human diligence — at each stage, clear criteria determine what advances automatically versus what escalates.
Input Ingestion & Enrichment
Raw inputs — documents, sensor data, user requests — are ingested and enriched with contextual metadata: source reliability scores, historical patterns, and domain tags. This context shapes downstream routing and confidence thresholds.
Model Inference & Confidence Scoring
The AI model processes enriched inputs and produces outputs accompanied by calibrated confidence scores, uncertainty intervals, and the factors most influential to its prediction — enabling reviewers to quickly understand the basis of any recommendation.
Intelligent Routing Engine
A rules-and-ML hybrid router classifies each output: auto-approve (high confidence, low stakes), human-review (medium confidence or high stakes), expert-escalate (novel situation or regulatory requirement), or reject-and-flag (potential adversarial input or policy violation).
Expert Review Interface
Reviewers interact with purpose-built interfaces that surface the AI’s reasoning, highlight decision-relevant evidence, and capture structured decisions with mandatory justifications. Time-on-task, inter-rater agreement, and decision rationale are logged for quality assurance.
Decision Enforcement & Audit Trail
Approved decisions are executed with full provenance: who decided, when, on what basis, and which AI outputs informed the choice. Immutable audit logs satisfy regulatory requirements and enable post-hoc investigation of any outcome.
Feedback Loop & Retraining Pipeline
Human decisions — especially overrides — are curated into training signal. The retraining pipeline continuously shifts the automation threshold: cases the model now handles confidently are removed from the review queue, freeing human capacity for genuinely novel challenges.
Critical Domain Applications
HITL is not a one-size-fits-all solution. Each domain demands different confidence thresholds, review expertise, latency tolerances, and regulatory frameworks. Here is how leading industries structure their human oversight layers.
Core Design Challenges
Designing effective HITL systems requires confronting fundamental tensions between speed and safety, scalability and thoroughness, and human capability and cognitive limitations. Understanding these challenges is a prerequisite for robust system design.
Reviewer Fatigue & Automation Bias
When AI accuracy is high, reviewers begin to rubber-stamp AI decisions — known as automation complacency. Conversely, high review volumes cause fatigue and error rates to rise. Well-designed interfaces counteract this through friction, randomized spot-checks, and reviewer performance metrics.
Finding the Right Automation Boundary
Setting confidence thresholds too conservatively floods reviewers; too liberally allows errors to slip through. The optimal threshold is domain-specific, time-varying, and requires continuous empirical calibration using real outcomes — not just model confidence scores.
Real-Time vs. Deliberate Review Tension
Many critical applications — emergency triage, fraud detection, autonomous vehicles — operate on millisecond to second timescales that fundamentally limit synchronous human review. HITL must be re-architected as asynchronous oversight, policy-setting, and post-hoc auditing in these contexts.
Economic Sustainability of Human Review
As AI systems process millions of decisions daily, the cost of human review can outpace the benefit. Sustainable HITL requires progressive automation — systematically retiring human review for tasks the model has mastered — while maintaining rigorous monitoring for distributional drift.
Implementation Best Practices
Leading organizations that have successfully deployed HITL systems at scale share a set of converging best practices — from interface design to governance structures — that distinguish robust implementations from fragile ones.
Design for the Reviewer, Not the Model
Review interfaces must surface the right evidence in the right order, within the reviewer’s cognitive bandwidth. Prioritize key signals, suppress irrelevant noise, and enforce structured decision capture.
Establish Graduated Automation
Begin with 100% human review in new domains. Systematically expand automation only when the model’s performance is validated on a holdout set representative of production data.
Monitor Override Rates Continuously
A sudden spike in human overrides signals model drift or a data shift before aggregate accuracy metrics detect it. Override rate is your early warning system.
Close the Feedback Loop Rapidly
Human decisions should feed into the model within days, not months. Delayed feedback loops allow the model to continue making avoidable errors and slow the path to higher automation rates.
Train Reviewers as AI Auditors
Human reviewers must understand AI failure modes — not just domain knowledge. Regular calibration sessions, adversarial examples, and bias awareness training are essential competencies.
Build Governance Before You Scale
Establish clear ownership, escalation paths, and review cadences before expanding the system’s scope. Governance retrofitted after scale is invariably incomplete and costly.
